
|
|
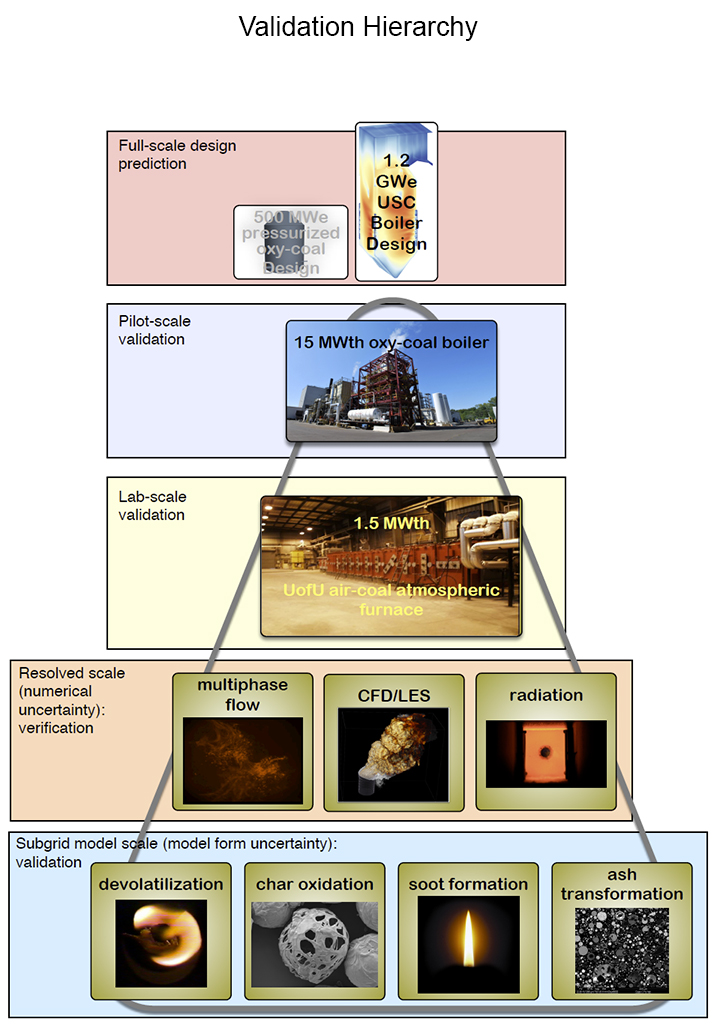
The CCMSC is organized around our validation hierarchy into three tightly coupled working teams: predictive science, exascale computing, and V&V/UQ.
Predictive Science Team
Led by Philip Smith and Tom Fletcher
The Predictive Science Team is focusing on four key physics components that will improve the predictivity of simulations of the 350 MWe oxycoal-fired boiler:
- turbulent fluid transport,
- multiphase flow,
- particle combustion, and
- radiative heat transfer.
Advances in these four areas will provide predictions of a wider range of phenomena, over a wider range of space and time scales, with improved predictive accuracy and reduced uncertainty, or at least a better understanding of the uncertainty in comparison to existing capabilities.We anticipate the majority of the disciplinary advances will come as a result of the tight coupling between the predictive science team with the exascale and V/UQ activities.
Exascale Computing and Software
Led by Martin Berzins
Our CCMSC will start with a proven computational platform (UintahX) and sequentially move to multipetaflop and eventually exascale computing. We will accomplish this transformation with three software infrastructure components: 1)the exascale runtime system, 2)TASC (Transparent Abstractions for Scalable Computing) representing a high-level, portable "assembly language" for scientific computation with transparent abstraction by using a sub-Turing, embedded domain-specific language, and 3) the data management and visualization infrastructure for dealing with large data and for connecting that data to the visualization and data analysis components.
The challenge is not only of running on machines such as Titan and Sequoia, but also in being able to run on at subsequent generations of parallel machines whose characteristics may include:
- Communications will be hierarchical in nature and potentially subject to long delays, thus requiring the overlapping of communication with computation.
- Compute nodes will have more cores and/or accelerators than at present.
- Compute nodes will have less memory per core. Each node will need to access shared memory abstractions that are lock-free and work with only one copy of global data per node.
- In order to achieve good future performance it will be necessary to tune the runtime system so as to detect and remove inefficiencies in scaling.
- The probability of associated soft and hard hardware faults on such machines is expected to be much greater than at present and will require resilient software.
- The need for energy efficiency requires that computational work be focused where it is needed by using techniques such as adaptive-mesh refinement guided by V/UQ.
- Careful orchestration and minimization of data movements needs to be a key design component in the software ecosystem since moving data is a major contributor to the energy cost of a simulation and the time delays introduced by traditional bulk data movements will introduce unacceptable utilization degradation of the overall computing resources allocated.
V&V/UQ Team
Led by Philip Smith, Eric Eddings, Andrew Packard, Michael Frenklach
The V&V/UQTeam will both provide the basis for risk assessment of the new technology and drive the technical priorities and resource allocation for the research within the CCMSC. The results of the V&V/UQ process will determine which physics and which framework components are critical to the Center's success. The V&V/UQ Team is organized into five groups from three institutions: verification, experimental data, surrogate model development, validation/uncertainty quantification, and tools creation.
Verification. Software verification is performed at a number of levels. First, formal verification analysis is performed, including: order of accuracy convergence for all spatial and temporal discretization, analytical solutions, and method of manufactured solutions. Second, regression testing is performed to ensure that the code base maintains its integrity.
Experimental data. The Experimental Data and Analysis Group is compiling and analyzing datasets from various sources for use in each brick of the the validation hierarchy, with a goal of exploring fire-side design constraints of a 350MWe high-efficiency ultra-supercritical oxy-coal power boiler. This group will focus on validation from bench to pilot-scale. Initial data sets will be provided early to facilitate preliminary simulations, followed by in-depth uncertainty evaluations of the early data sets to facilitate subsequent consistency analyses. Alstom's participation in this group is key to its success.
Surrogate model development. To explore the uncertainty space for the V/UQ analysis we cannot afford to perform an exascale simulation for each function evaluation. The Surrogate Model Creation and Analysis Group is developing surrogate models that can be used to faithfully reproduce the output function (quantity of interest for the intended use of the simulation, i.e. heat flux distribution) as a function of the uncertain parameters for the V/UQ analysis to follow.
Tools Creation. The Tools Group is developing revolutionary algorithmic, theoretical, computational and mathematical frameworks that forms the foundation of the deterministic (Bound-to-Bound Data Collaboration) and the probabilistic (Bayesian) approaches. These tools will then be used by the V/UQ Analysis Group to perform the UQ-predictive analysis of the CCMSC overarching problem